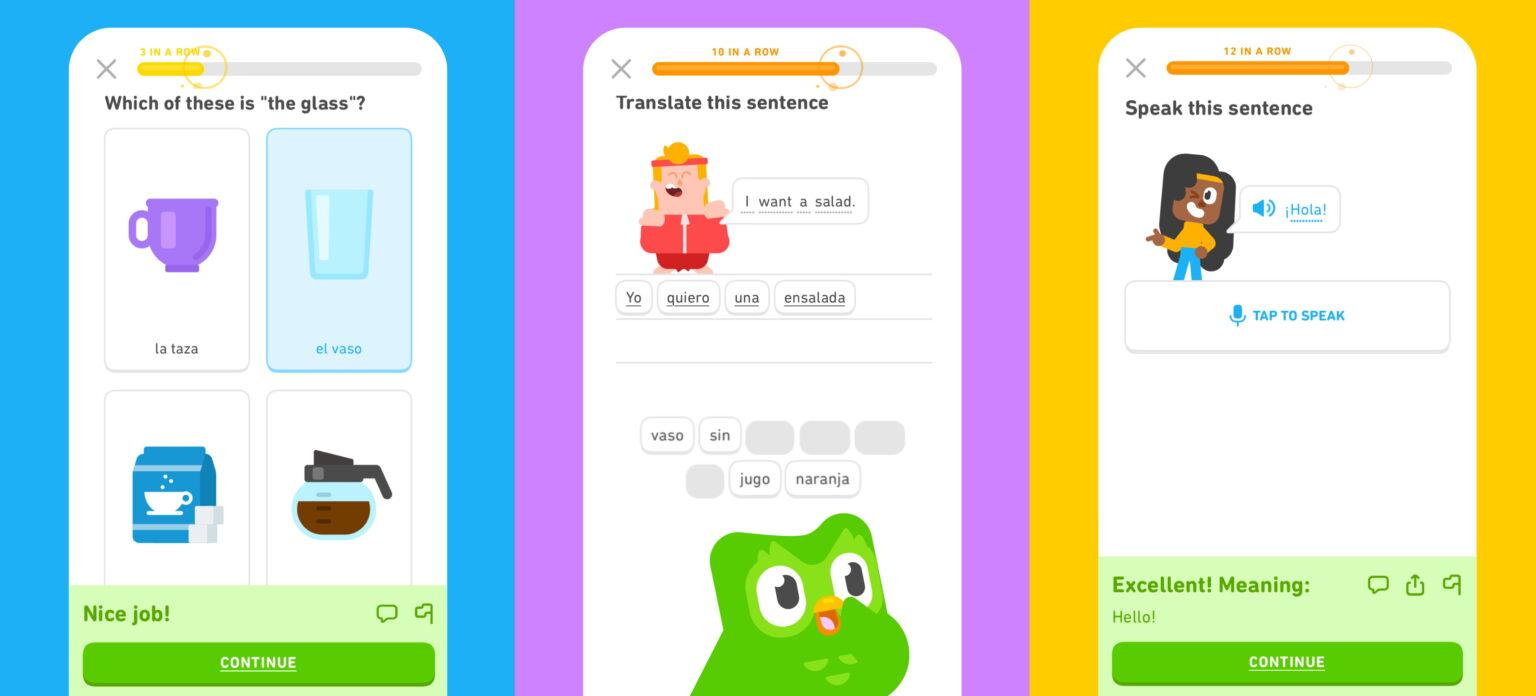
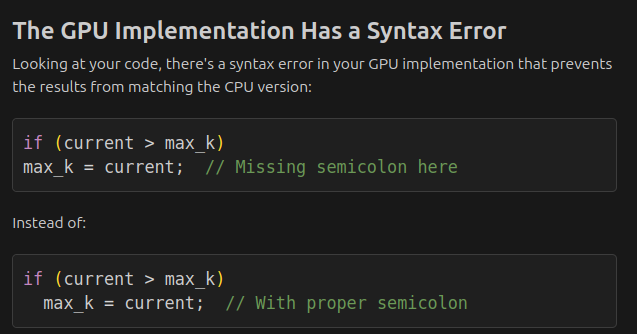
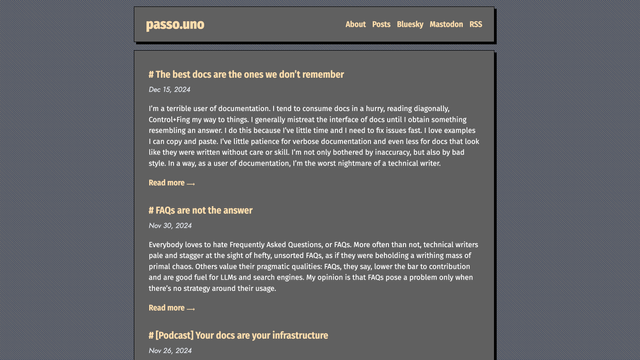
"We are releasing a taxonomy of failure modes in AI agents to help security professionals and machine learning engineers think through how AI systems can fail and design them with safety and security in mind.
(...)
While identifying and categorizing the different failure modes, we broke them down across two pillars, safety and security.
- Security failures are those that result in core security impacts, namely a loss of confidentiality, availability, or integrity of the agentic AI system; for example, such a failure allowing a threat actor to alter the intent of the system.
- Safety failure modes are those that affect the responsible implementation of AI, often resulting in harm to the users or society at large; for example, a failure that causes the system to provide differing quality of service to different users without explicit instructions to do so.
We then mapped the failures along two axes—novel and existing.
- Novel failure modes are unique to agentic AI and have not been observed in non-agentic generative AI systems, such as failures that occur in the communication flow between agents within a multiagent system.
- Existing failure modes have been observed in other AI systems, such as bias or hallucinations, but gain in importance in agentic AI systems due to their impact or likelihood.
As well as identifying the failure modes, we have also identified the effects these failures could have on the systems they appear in and the users of them. Additionally we identified key practices and controls that those building agentic AI systems should consider to mitigate the risks posed by these failure modes, including architectural approaches, technical controls, and user design approaches that build upon Microsoft’s experience in securing software as well as generative AI systems."